rand_forest(
mode = "unknown",
engine = "ranger",
mtry = NULL,
trees = NULL,
min_n = NULL
)Tree-Based Methods
POLI_SCI 490
Maybe?

Maybe not?

Regression/classification trees
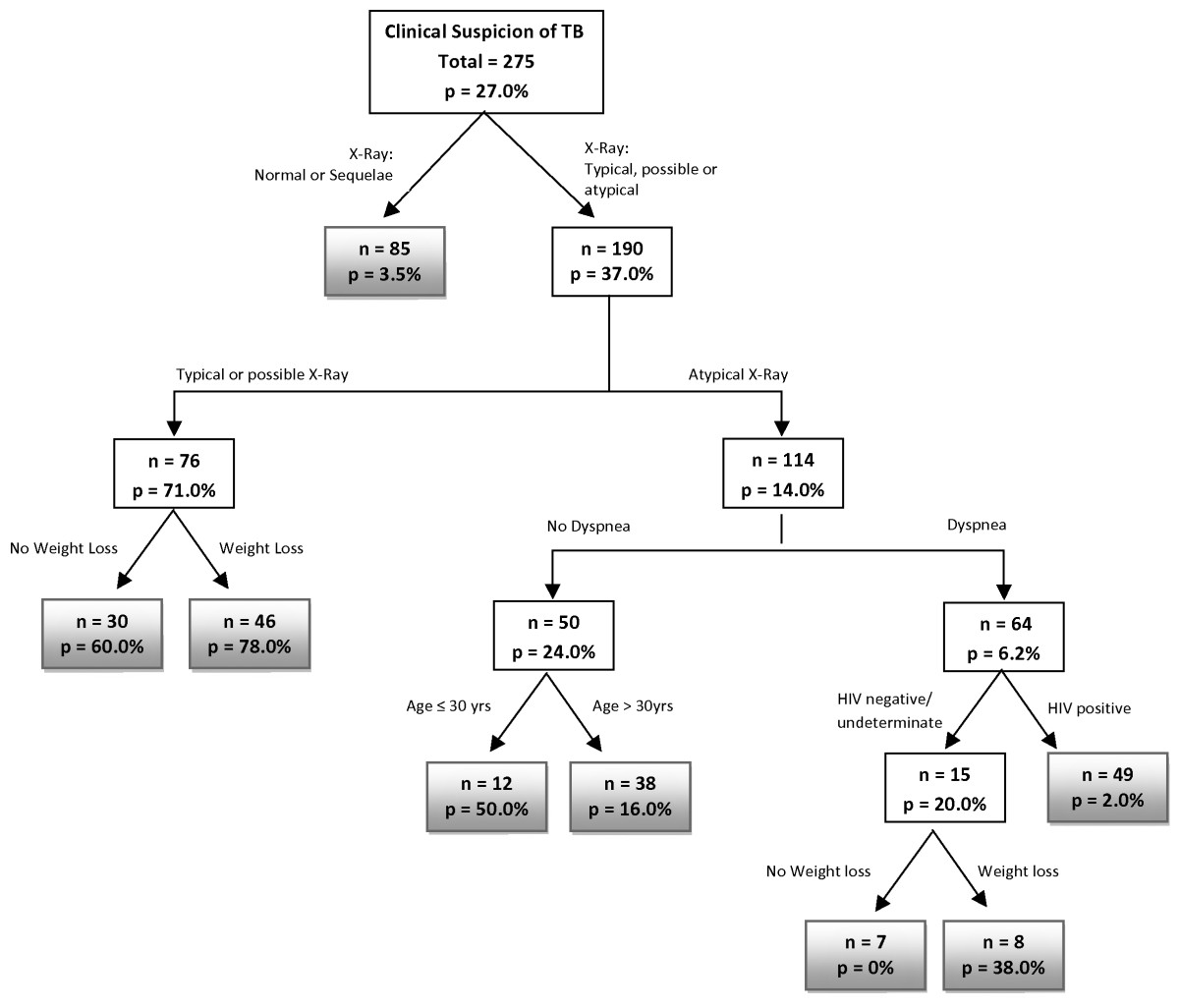
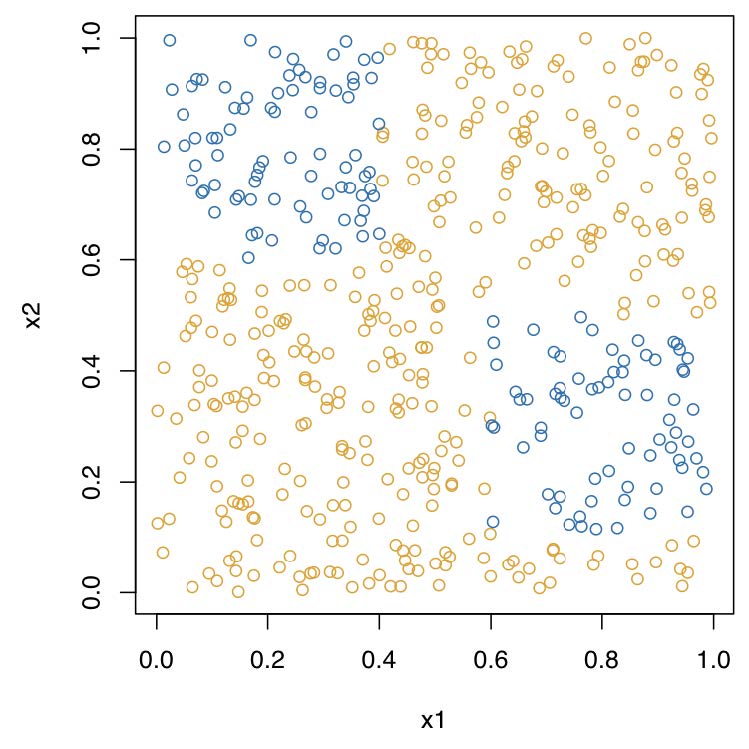
Recursive binary partitioning
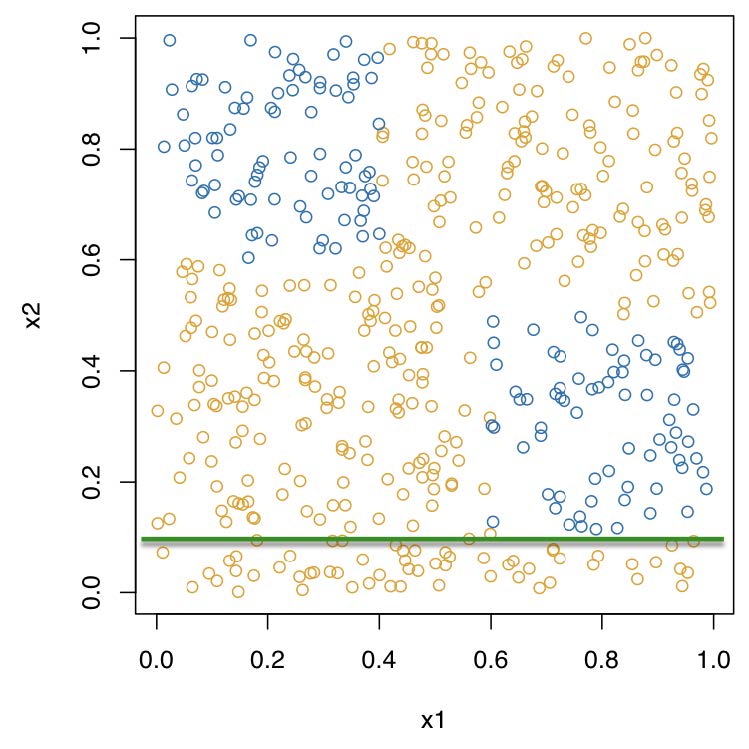
Recursive binary partitioning
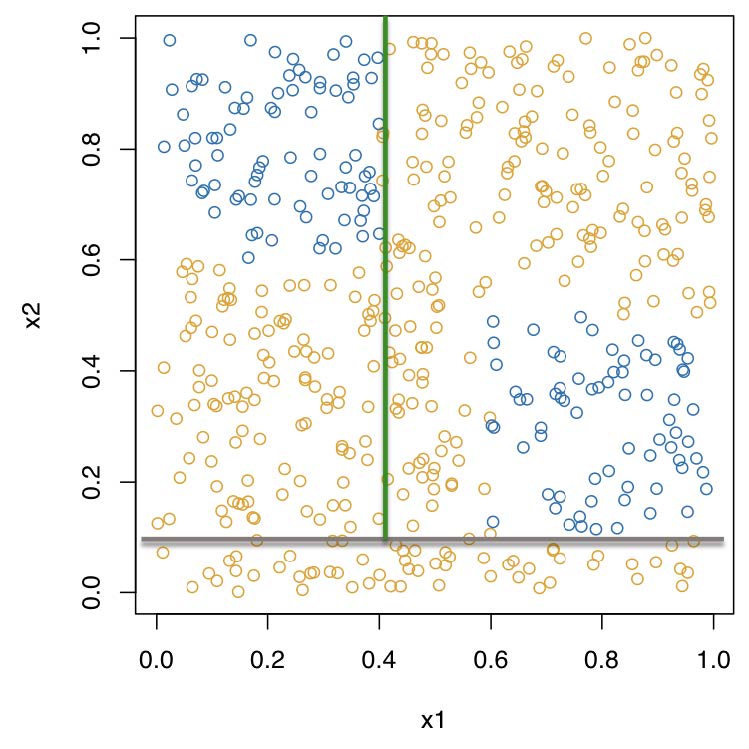
Recursive binary partitioning
Recursive binary partitioning
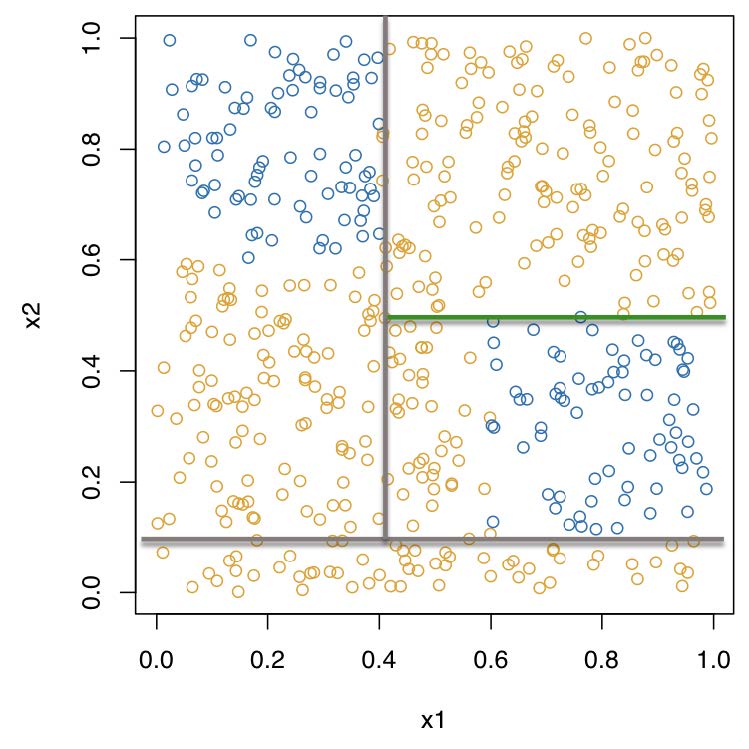
Recursive binary partitioning
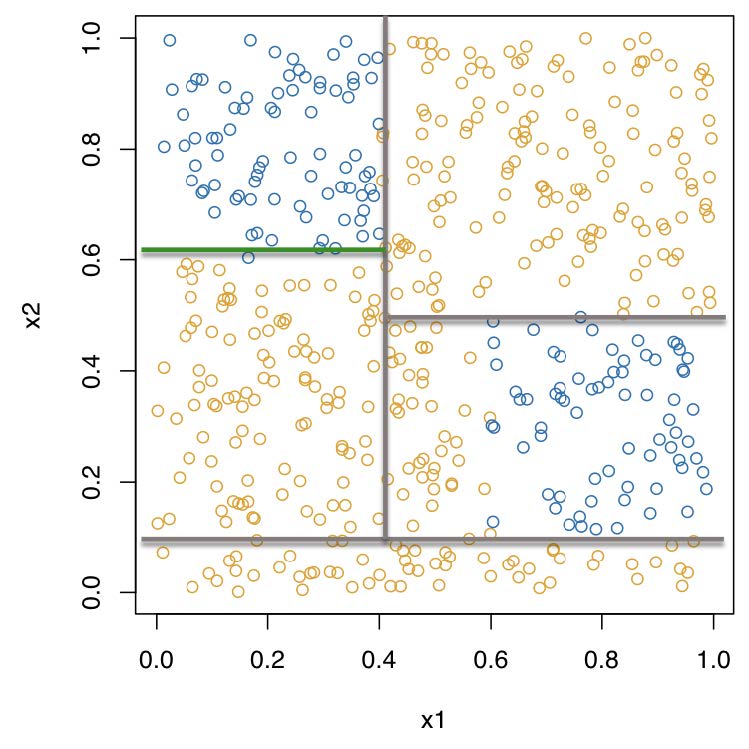
Recursive binary partitioning
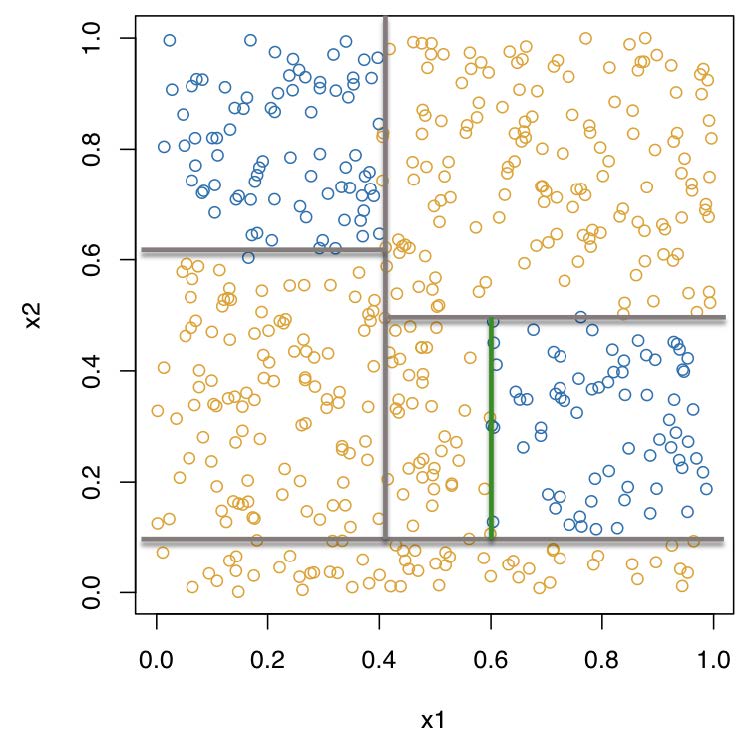
Bagging
Bootstrap AGGregatING
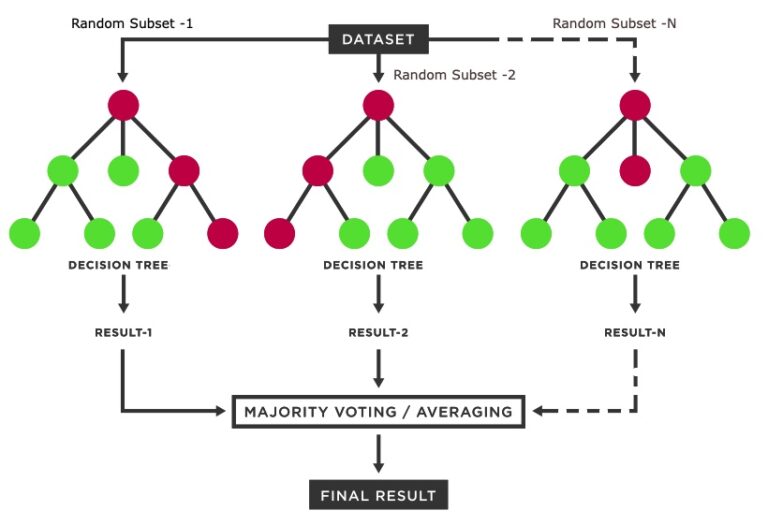
More formally (ISL p. 347)

Random forest: Decorrelated trees
Boosting: Grow trees sequentially

BART
Bayesian Additive Regression Trees
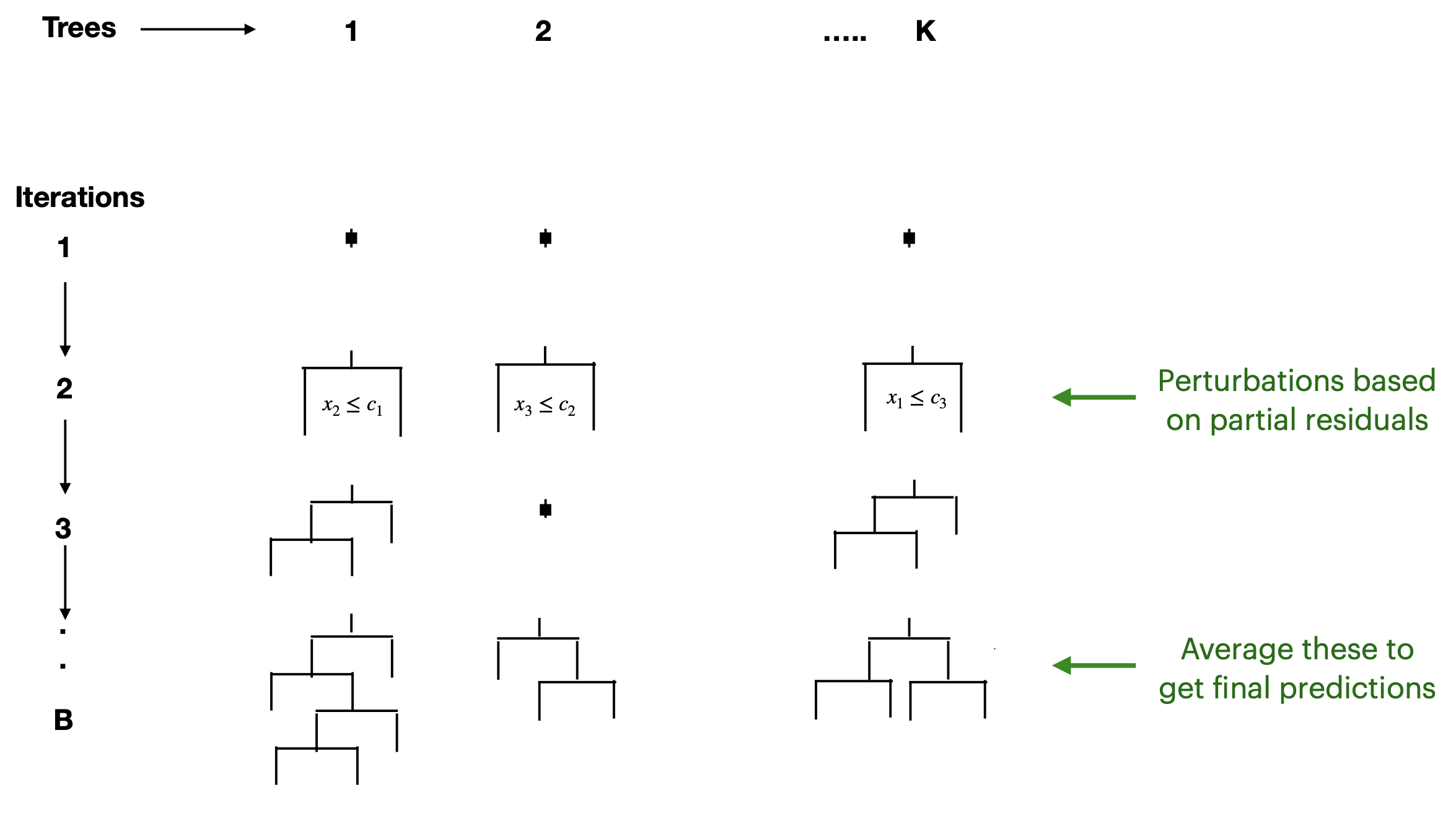
Examples of perturbations
